AI MONITORING · COST TRACKING
Per-call AI spend, broken down the way you need it.
Total spend, per-app spend, per-model spend — by team, use case and time. Forecasts and alerts before the bill hits.
Cost Tracking captures every Gateway call with model, latency and token counts attached. Roll it up by app, team, use case, model or provider — whichever cut answers your question.
The price gap between a frontier model and a small one is often two orders of magnitude. Customers regularly cut spend 90% on routable workloads once the data shows where to route.
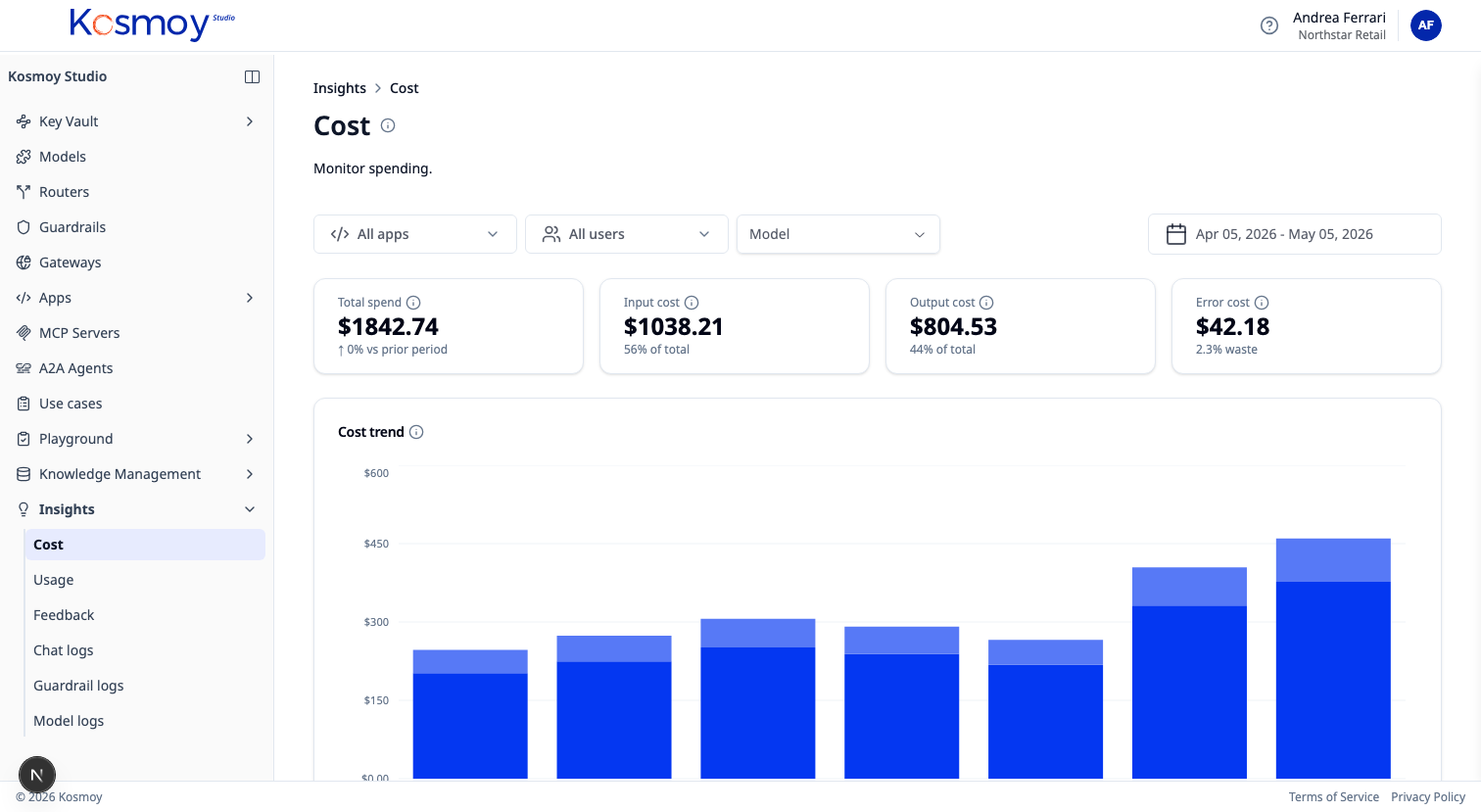
What it does.
Per-call attribution
Every call tagged with model, app, team, use case, environment, time.
Multi-dimension rollups
Cut spend by any combination of those dimensions.
Forecasts
30-day moving forecasts on every dimension. Trend lines for executives.
Budget alerts
Soft and hard caps per app, team, use case. Alert before breach.
Chargeback exports
CSV and API exports for finance systems and internal billing.
Routing feedback loop
Feeds the LLM Router so simple prompts move to cheaper models.
Module questions, answered straight.
How granular is the cost data?
Per call. Aggregated by app, team, use case, model, provider, environment and time period. Exportable as CSV or via API.
Does it support per-tenant chargeback?
Yes. Tag every call with a chargeback dimension and the dashboard breaks down spend by that dimension automatically.
Can it forecast spend?
30-day moving forecasts at the model, app and use-case level. Alerts fire before a budget is breached, not after.
See per-call AI cost in production.
Walk through real spend data and the routing optimisation loop.