AI MONITORING · USER FEEDBACK TRACKING
Quality, not just cost.
Every thumbs-up and thumbs-down connected to the prompt, model and retriever that produced the answer.
Cost without quality is a rounding-down exercise. Kosmoy joins user feedback to the same event stream as cost and latency, so every routing decision can be tested against what users actually preferred.
Drill into the negative-feedback set, see which prompt template or model is responsible, and adjust without guessing.
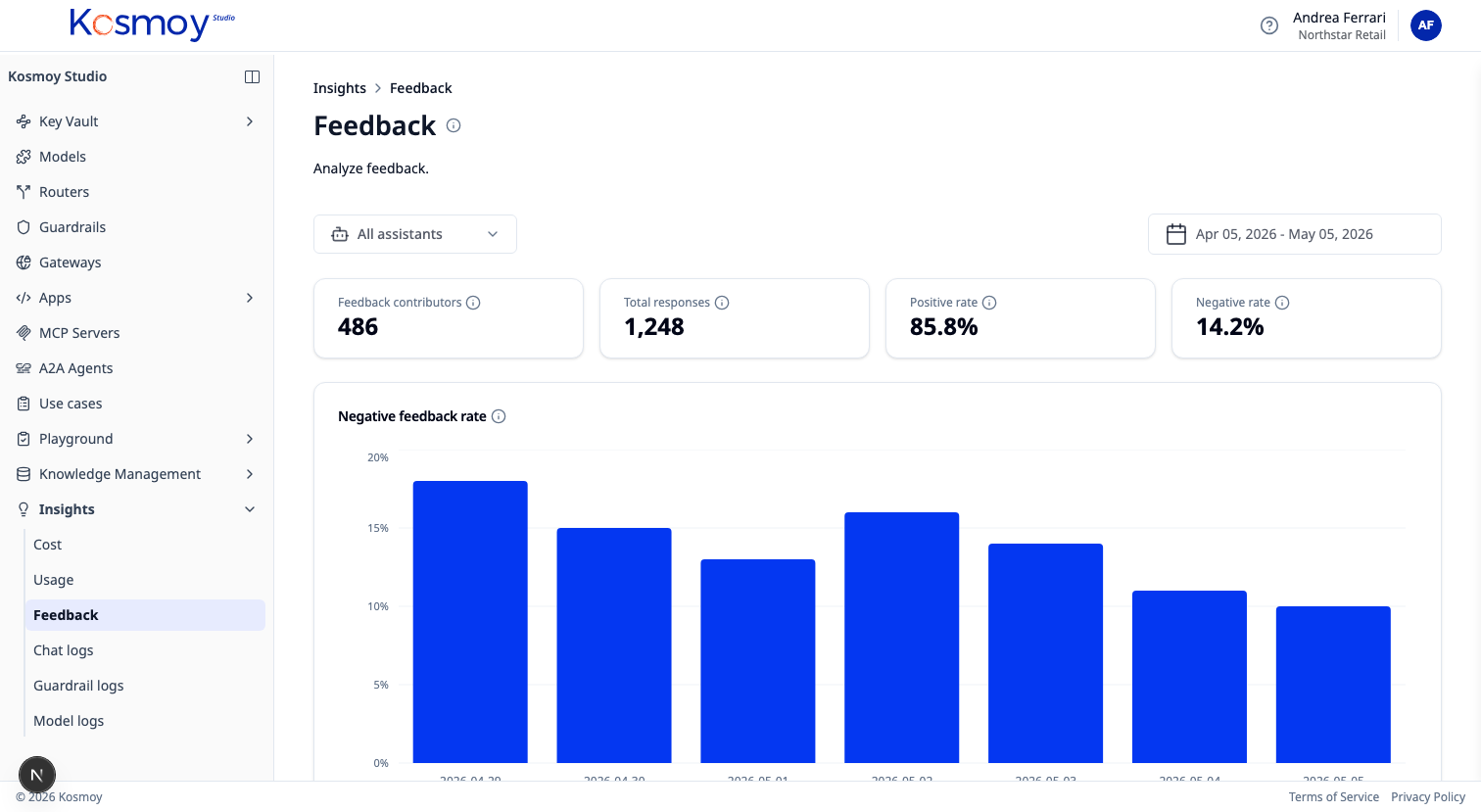
What it does.
Thumbs + ratings
Up/down, plus structured 1–5 ratings where the use case warrants.
Categorical breakdown
"Wrong info", "didn't understand", "too slow" — searchable per app.
Per-model rollup
Negative feedback rate by model and prompt version, side by side.
A/B testing
Run two models on the same use case and compare feedback over a window.
Drilldown to call
Click a feedback event and see the exact prompt, response and routing decision.
Routing feedback loop
Feeds the LLM Router so quality holds when cost is cut.
Module questions, answered straight.
Where does feedback come from?
Thumbs up/down and structured ratings inside Kosmoy Chat, plus any custom collection points your apps surface. Each piece of feedback is tagged to the specific call, model and prompt version that produced the answer.
How does it correlate with cost and model?
Feedback joins the same event stream as cost, latency and policy events. The dashboard shows negative-feedback rate by model, prompt version and app — so you can see whether a cheaper model is actually performing.
Can we A/B-test models with it?
Yes. Run two models on the same use case for a window, compare feedback rate, and keep the route that wins.
See user feedback connected to model and prompt.
Walk through real negative-feedback drilldown and an A/B test.