Most enterprises think they are running one LLM. The reality is closer to five.
There is the OpenAI API that the product team integrated eighteen months ago. There is the Azure OpenAI deployment the security team approved because it kept data in the EU. There is the Anthropic Claude access the legal team set up independently because they preferred the reasoning style. There is the self-hosted Llama instance the ML team spun up for a cost experiment that never quite ended. And there is the model embedded in the SaaS productivity tool that nobody in IT specifically approved but everyone is using.
This is not a pathological situation. It is the ordinary result of AI adoption moving faster than centralized procurement. And it creates a structural problem that no amount of policy documentation can fix: when you have more than one LLM and no AI Gateway, you have no single point at which governance, cost control, and compliance logging can be enforced. You have as many governance implementations — inconsistent, incomplete, and invisible to each other — as you have LLM integrations.
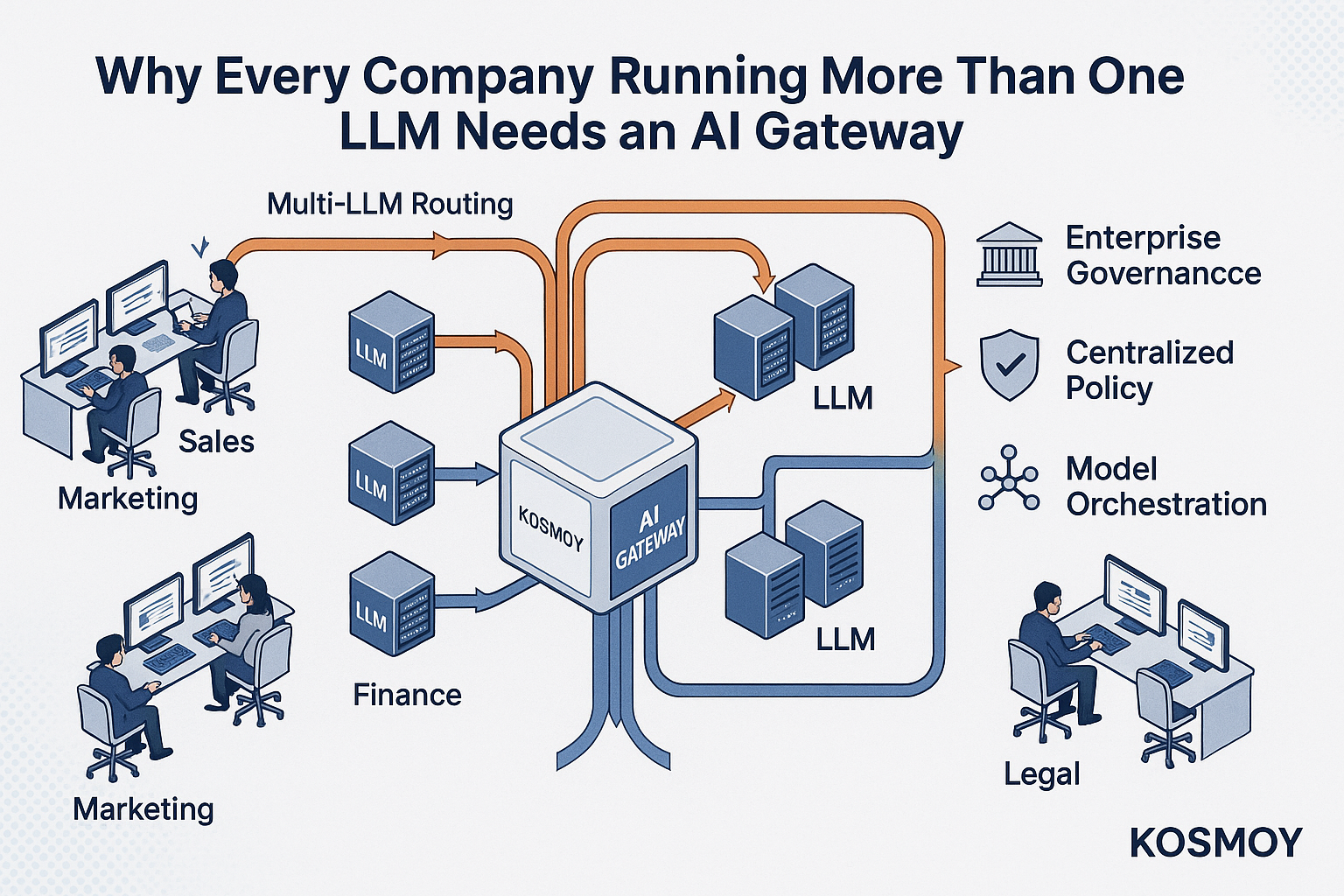
An AI Gateway changes this. Not by limiting what models the organization can use, but by becoming the layer through which all of them are used.
The Multi-LLM Reality
The shift from single-model to multi-model environments happened faster than most enterprise IT teams expected. Three forces drove it.
Model specialization
No single model is best at every task. GPT-4o handles code generation and structured extraction well. Claude excels at long-document reasoning and nuanced instruction following. Gemini is competitive on multimodal tasks. Smaller open-weight models — Llama, Mistral, Phi — can match larger commercial models on constrained, well-defined tasks at a fraction of the cost. Enterprises that limit themselves to one provider leave performance and cost efficiency on the table.
Cost pressure
Large frontier models are expensive for high-volume, lower-complexity tasks. A question-answering workflow that routes every query to GPT-4o will cost ten to twenty times more per token than the same workflow using an appropriately sized model for routine queries and reserving the frontier model for genuinely complex ones. Organizations that have audited their LLM spend consistently find that 60–80% of their token consumption is going to models that are overqualified for the task.
Regulatory and data residency requirements
Regulated enterprises — financial services, healthcare, defense, public sector — often cannot route all AI traffic through a single commercial provider. Different departments face different data residency rules. EU-regulated entities may require that personal data not leave the European Economic Area. Certain government and defense workloads require self-hosted or air-gapped model deployments entirely. Multi-LLM is not an architectural preference in these environments. It is a compliance requirement.
The result: most mature enterprise AI programs are running three to seven distinct model endpoints within eighteen months of serious adoption, often without a centralized view of any of them.
What Breaks When You Have Multiple LLMs and No Gateway
Running multiple LLMs without a centralized gateway creates the same class of problems that running multiple databases without a data platform creates: each integration works, in isolation, but the system as a whole is ungovernable.
Governance is implemented N times, inconsistently
Every team that integrates an LLM builds its own guardrails, its own access control logic, its own logging. They build it with different tools, to different standards, with different levels of rigor. Some teams implement PII filtering. Others don't. Some log prompts and completions. Others log nothing. Some enforce content policies. Others rely on the model's default behavior.
The result is a governance posture that looks solid from a distance — each team has "their own" controls — and is full of gaps in practice. The gaps are invisible to anyone with cross-team accountability: a CISO, a compliance officer, a regulator conducting an audit.
Cost attribution is impossible
Without a gateway, LLM spend is attributed at the level of the billing relationship: OpenAI invoices come to one cost center, Azure OpenAI to another, Anthropic to a third. Nobody has a view of total AI spend by department, by use case, or by model. Nobody can answer "which team is consuming the most tokens" or "what is our token cost per customer support ticket" or "which three workflows account for 70% of our AI budget."
This is not a reporting inconvenience. It is the absence of the data required to make rational cost optimization decisions.
There is no audit trail
Regulators — particularly under the EU AI Act, DORA, and sector-specific frameworks — require evidence of human oversight, risk management, and continuous monitoring of AI systems. That evidence takes the form of structured logs: what the system received, what it produced, what policy decisions were applied, and what the outcome was.
Without a gateway, this log is fragmented across N separate systems, each with its own schema, its own retention policy, and its own access controls. Producing a coherent audit trail for a single AI-driven process that touched three different models requires reconstructing it from three separate sources — assuming all three logged anything at all.
Model switching is expensive
Without a gateway, every model change requires a code change. The application is wired directly to the model endpoint, and the model's API signature, authentication mechanism, and parameter schema are embedded in application code. Switching from GPT-4o to Claude requires touching every application that calls GPT-4o. Switching for a subset of traffic — to test a new model, respond to a price change, or satisfy a new data residency requirement — requires forking the application logic.
At small scale this is manageable. At the scale of dozens of teams and hundreds of integrations, it is a meaningful engineering liability.
What an AI Gateway Does
An AI Gateway is the centralized layer through which all LLM traffic in an organization passes. Every model call — regardless of which application made it, which team owns that application, or which model endpoint it targets — routes through the gateway. The gateway handles the translation, the policy enforcement, and the logging. Applications call the gateway; the gateway calls the models.
This single architectural decision resolves every problem described above.
One policy enforcement point for all models
Guardrails configured at the gateway apply to every LLM call, regardless of source. A content policy that filters toxic language, screens for PII, and checks for prompt injection is written once and enforced uniformly — whether the call is going to OpenAI, Anthropic, a self-hosted Llama instance, or an Azure deployment. Teams build their applications without implementing governance logic. The governance layer handles it.
The practical implication for compliance: the evidence that governance was applied is generated in one place, in a consistent schema, for every interaction the organization has ever had with an LLM. An audit that took weeks to reconstruct from disparate logs becomes a structured query.
Intelligent routing across models
A gateway can route individual requests to the most appropriate model based on rules the organization defines: request complexity, cost budget, latency requirements, data residency constraints, or model capability. A simple customer service query routes to a small, fast, cheap model. A complex contract analysis routes to the frontier model with the longest context window. A query containing personal data routes to the EU-resident deployment.
This routing logic lives in the gateway — not in application code — which means it can be updated, tested, and optimized without touching the applications that consume it. Model transitions become configuration changes. A/B testing new models becomes a routing rule, not a deployment.
Real-time cost attribution
Every request passing through the gateway is logged with the organizational metadata that makes cost attribution meaningful: which team initiated it, which application sent it, which use case it belongs to, how many tokens it consumed, and what it cost. Cost visibility becomes a real-time operational capability, not a retrospective invoice reconciliation exercise.
With this data, the questions that previously had no answers become answerable: which departments are driving the most spend, which use cases have the worst token efficiency, what the fully-loaded AI cost per unit of business output is.
A single audit trail
The gateway generates a structured, complete, tamper-evident log of every LLM interaction: the request, the response, the model used, the policies applied, the policy outcomes, the latency, the cost, and the organizational context. This log is the audit trail that regulators require and that incident investigation depends on. It exists whether or not the teams building applications thought to implement logging themselves.
The API Gateway Analogy — and Where It Breaks Down
Enterprise architects will recognize this pattern from service-oriented architecture: the API gateway as a centralized policy enforcement and observability point for microservice traffic. The AI Gateway is conceptually similar, but the LLM context introduces requirements that traditional API gateways were not built for.
A traditional API gateway operates on HTTP traffic with deterministic request and response schemas. It enforces authentication, rate limiting, and routing based on URL patterns and headers. These are structural properties of the traffic that can be evaluated without understanding the content.
LLM calls require content-aware processing that API gateways cannot perform:
- Semantic content analysis — evaluating whether a prompt contains PII, toxic language, prompt injection attempts, or policy-violating requests requires understanding the natural language in the payload, not just its structure.
- Token-level cost tracking — LLM cost is denominated in tokens, not in requests. Meaningful cost attribution requires parsing the response to extract token counts and mapping them to organizational metadata.
- Response quality evaluation — monitoring for hallucination signals, output relevance, and consistency requires evaluating model outputs against expected behavior, not just checking HTTP status codes.
- Context window management — in multi-turn conversations and agentic workflows, the gateway needs to manage what context is passed forward, how it is summarized, and when it is truncated, to avoid exceeding model limits while preserving conversation integrity.
- Agent-specific controls — for autonomous agents that make sequences of LLM calls as part of a workflow, the gateway needs to enforce scope constraints, execution budgets, and authorization checks at each step, not just at the boundary of a single request.
Traditional API gateways handle the transport layer. An AI Gateway handles the semantic layer. They are not substitutes.
The Right Time to Implement an AI Gateway
The right time to implement an AI Gateway is before the second LLM integration goes live. In practice, most enterprises implement it after the third or fourth, once the governance and cost problems are already visible.
The cost of implementing a gateway after the fact is real but finite: existing integrations need to be rerouted through the gateway, which is straightforward if the gateway exposes an OpenAI-compatible API (existing code requires no changes for OpenAI-compatible integrations). The cost of not implementing one compounds: every new LLM integration without a gateway adds another fragmented governance implementation, another unattributed cost center, and another gap in the audit trail.
If your organization is using more than one model today — or planning to — the question is not whether an AI Gateway is necessary. It is how much longer to run without one.
How Kosmoy's AI Gateway Works
The Kosmoy AI Gateway is the centralized policy enforcement and routing layer for every LLM, MCP, and agent-to-agent call in your organization.
OpenAI-compatible API surface. Existing applications that call OpenAI endpoints can route through the Kosmoy Gateway without code changes. The gateway translates to the appropriate downstream model — whether that is GPT-4o, Claude, Gemini, a self-hosted Llama deployment, or any other supported provider.
Policy enforcement at the gateway layer. Guardrails for PII detection, toxic content, prompt injection, and custom business rules are configured once and applied to every call, regardless of source. Teams build applications; the platform handles compliance.
Cost attribution by team, application, and use case. Every token consumed is logged against the organizational metadata that makes it actionable. Real-time cost dashboards require no additional instrumentation in applications.
Complete, structured audit log. Every interaction — request, response, model, policy outcome, latency, cost — is logged in a structured, queryable format. The audit trail exists by default, not by choice.
Intelligent routing. Traffic can be routed based on cost budgets, capability requirements, latency targets, or data residency rules. Model transitions and cost optimization strategies are configuration changes in the gateway, not code changes in applications.
MCP and agent-to-agent support. The Kosmoy Gateway handles not only direct LLM calls but also MCP tool invocations and agent-to-agent traffic — enforcing the same policy layer across the full surface of modern AI architectures.
The gateway is part of the Kosmoy platform, alongside AI Inventory (centralized registry of every AI system), Mission Control (fleet-level observability), and Action Capsules (Kubernetes-native agent sandboxing). It runs in your own Kubernetes on Azure, AWS, GCP, or on-prem.
Frequently Asked Questions
What is an AI Gateway? An AI Gateway is the centralized layer through which all LLM traffic in an organization passes. It handles policy enforcement (guardrails, access control, compliance rules), intelligent routing across model providers, cost attribution at the request level, and structured audit logging — for every LLM call, regardless of which application or team initiated it.
Why do multi-LLM environments specifically require an AI Gateway? In a single-LLM environment, governance logic can be implemented inside the application that calls the model — imperfectly, but feasibly. When the organization runs multiple LLMs, governance is implemented N times by N different teams with N different standards and N different gaps. An AI Gateway is the only architecture that provides a single, consistent policy enforcement point across all of them.
How is an AI Gateway different from a traditional API gateway? A traditional API gateway routes HTTP traffic based on structural properties — URL patterns, headers, authentication tokens. An AI Gateway processes the semantic content of LLM calls: it evaluates natural language payloads for PII and policy violations, tracks token-level costs, manages context windows for multi-turn interactions, and applies agent-specific controls. These capabilities require LLM-specific logic that traditional API gateways do not provide.
Does an AI Gateway create a single point of failure? A well-architected AI Gateway is deployed with high availability — multiple replicas, failover, and health checks. The risk of a single point of failure is an argument for building the gateway correctly, not for avoiding it. The alternative — distributed governance with no central enforcement point — creates a different and harder-to-manage class of failure: governance gaps that are invisible until an audit or an incident surfaces them.
Can the AI Gateway route traffic to self-hosted or private models? Yes. The Kosmoy AI Gateway supports routing to any model endpoint, including self-hosted open-weight models running in your own infrastructure. This is a requirement for regulated industries where certain workloads cannot be sent to commercial providers.
What happens to existing LLM integrations when we add an AI Gateway? If the gateway exposes an OpenAI-compatible API surface — which the Kosmoy AI Gateway does — existing applications that call OpenAI endpoints require no code changes. They are reconfigured to point at the gateway instead of directly at the provider. The gateway handles the downstream routing transparently.
What governance standards does an AI Gateway help satisfy? The structured audit logging, policy enforcement, and cost attribution capabilities of an AI Gateway directly support the requirements of the EU AI Act (audit trails, human oversight evidence, risk management documentation), DORA (ICT risk management, operational resilience), and GDPR (data processing records, PII handling evidence). For sector-specific frameworks in financial services, healthcare, and defense, the same underlying capabilities satisfy the AI-related provisions of those frameworks.
Is an AI Gateway only relevant for large enterprises? Any organization running more than one LLM integration — regardless of size — faces the governance fragmentation problem an AI Gateway solves. The threshold is not headcount or revenue. It is the moment a second model endpoint goes live without a centralized control layer.