Built-in
Toxic content
Hate speech, harassment, violence. Configurable thresholds. Multilingual.
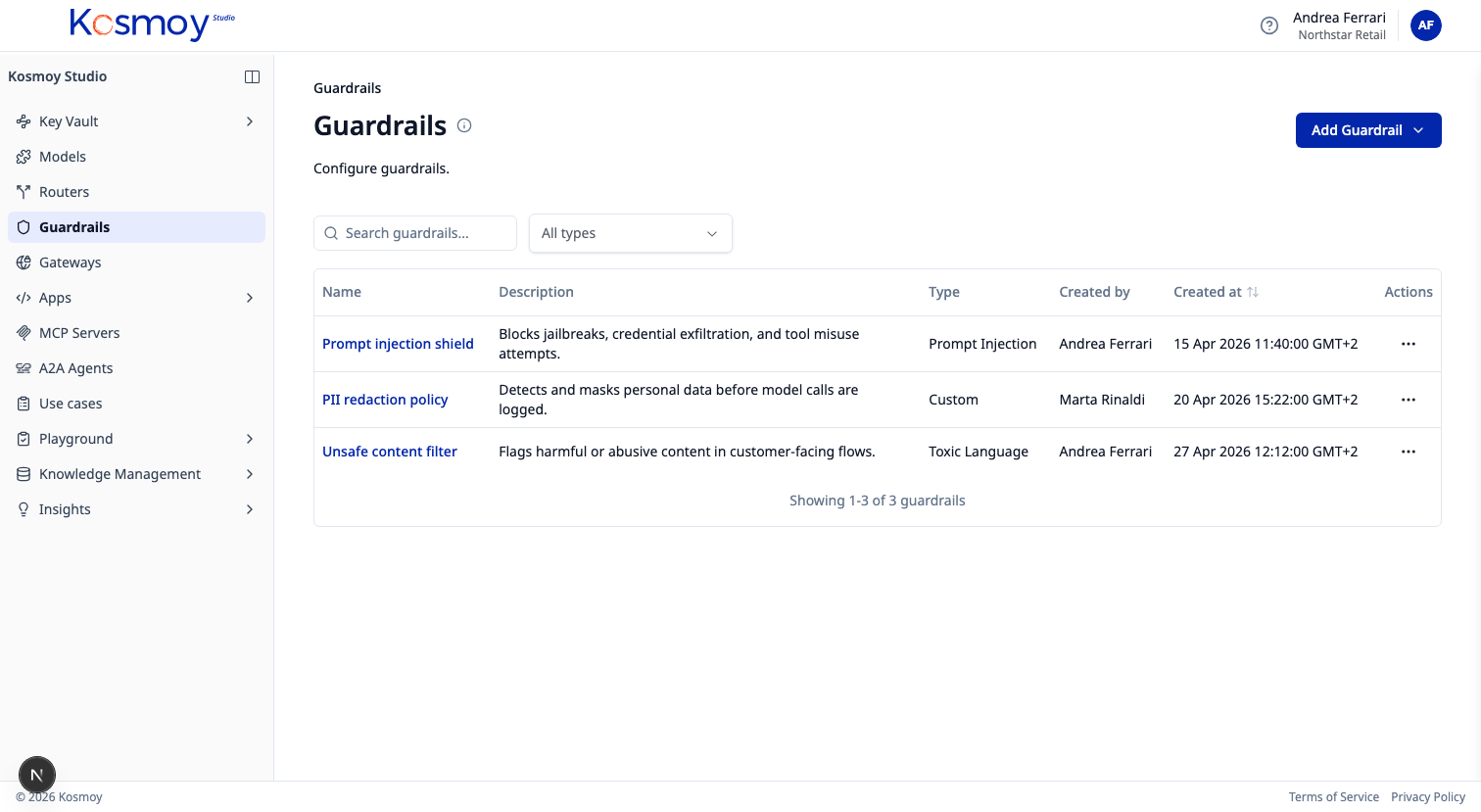
AI GUARDRAILS
Guardrails should not be optional code snippets bolted onto each application. In Kosmoy they run inside the Gateway path, applied the same way across every app, assistant, RAG system, and agent.
Three layers of enforcement: built-in configurable categories, customer-specific custom rules, and fine-tuned small language models for fast pattern checks at scale.
Each guardrail decision is an event. Allow. Block. Redact. Route to human review. Log. Every event lands in the Insights Dashboard and the AI Act dossier — searchable, exportable, and connected to the use case.
Built-in
Hate speech, harassment, violence. Configurable thresholds. Multilingual.
Built-in + fine-tuned SLM
Email addresses, phone numbers, government IDs, payment data. Block, redact, or log.
Built-in + fine-tuned SLM
Detect attempts to override system instructions, exfiltrate prompts, or chain-of-trust break-ins.
Built-in
Article 5 prohibited practices. Article 50 transparency triggers. Custom risk categories per the org.
Custom
Internal product names, vendor names, regulated terms, blocklists, allowlists.
Custom
Bring your own judge prompt and evaluator model. For domain-specific policies that don't fit the built-in categories.
Every rule produces one of five decisions: allow, block, redact, review (route to human), log. Configurable per rule, per route, per environment.
Per use case. Some apps need full enforcement; some need logging-only; some need none. The Gateway lets the platform team configure guardrails per route, per app, per environment.
Built-in regex and list checks are sub-10ms. Fine-tuned SLM-based guardrails are sub-200ms. Frontier-model judges (when explicitly enabled) are slower and used only where policy demands them.
Yes. Each guardrail rule has five outcomes — allow, block, redact, review (route to human), log. Most PII rules in production redact + log; toxic content rules block + log; injection attempts block + log + alert.
Every guardrail decision is an event with the input, the rule that triggered, the outcome, the model, the user, the timestamp. Events land in the Insights Dashboard and the AI Act dossier.
Walk through built-in, custom, and SLM-based enforcement on real prompts.