RAG-IN-A-BOX
Production RAG without the months of Python.
Ingest documents. Chunk and embed. Retrieve. Govern the answer. Connect your vector DB. Ship in days, not months.
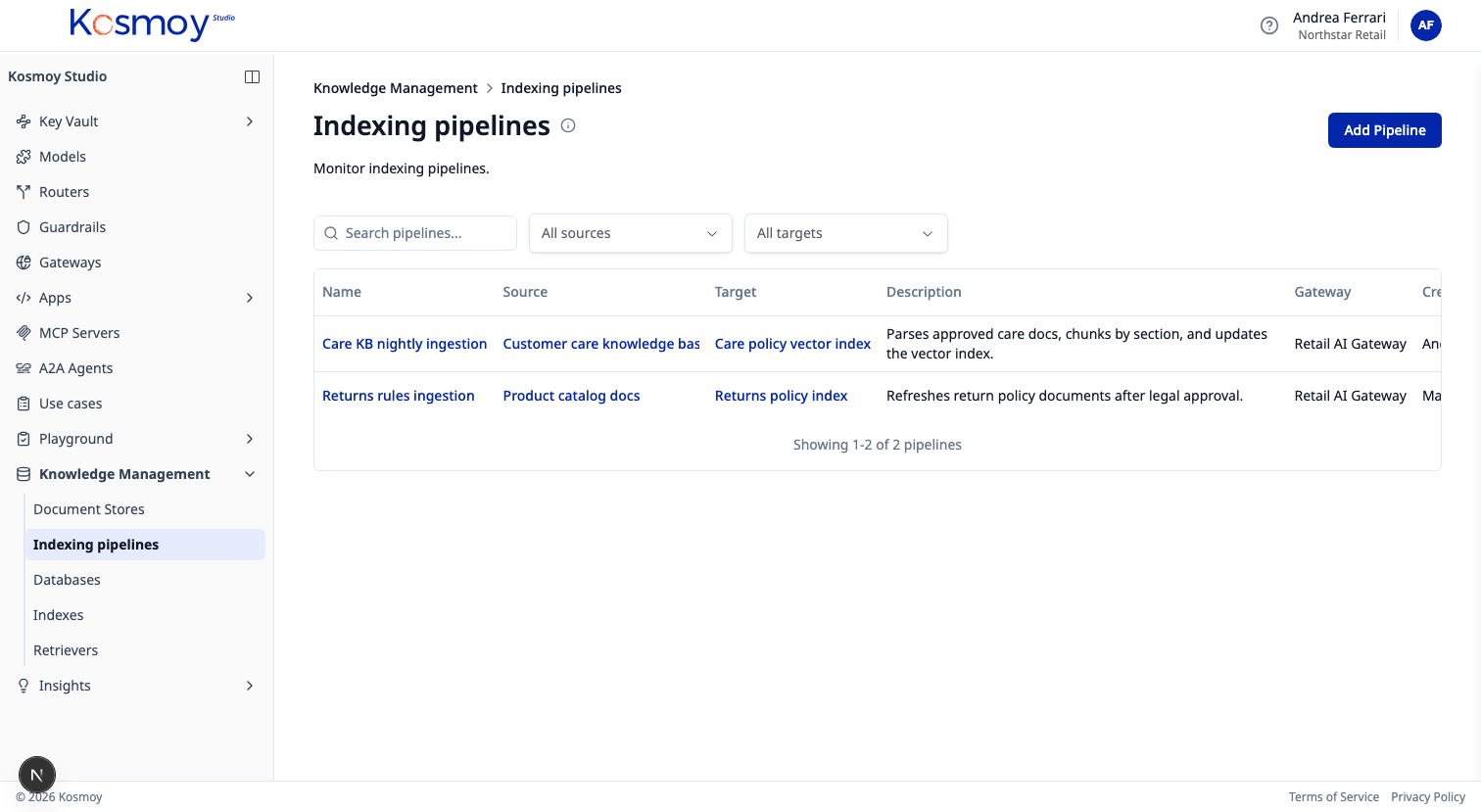
Four stages. All pre-built.
Ingestion
- Connect object stores, file stores, SharePoint, Confluence, Salesforce, ServiceNow
- Parse documents — text, tables, images, graphs
- Chunking strategies — max-size, hierarchical, hybrid
- Standard and custom metadata capture
Vectorization
- Embeddings (provider-agnostic)
- Record manager with deletion strategies
- Load to Snowflake, Databricks, Pinecone, Weaviate, Vertex, pgvector, on-prem
Retrieval
- Multi-query rephrase, self-query
- Lexical, semantic, hybrid
- Re-ranking and filtering
- Source-document filtering by user permissions
Answer path
- Routed via the AI Gateway
- Guardrails enforced
- Citations, conversation logs, feedback to Insights
Months of custom Python vs days with Kosmoy.
| Pattern | Months of custom Python | Days with Kosmoy |
|---|---|---|
| Document ingestion | Build extractors per format | Pre-built |
| Chunking and embeddings | Pick libraries, tune params | Configured no-code |
| Retrieval pipeline | Build, tune, evaluate | Built-in lexical, semantic, hybrid |
| Prompt management | Hand-rolled versioning | Versioned, diffable |
| Guardrails | Roll-your-own checks per app | Gateway-enforced |
| Model fallback | Custom retry logic | Algorithmic router |
| Cost tracking | Logs, scripts, spreadsheets | Insights Dashboard |
| QA before rollout | Ad-hoc | Recorded sessions |
Module questions, answered straight.
Does it work with our existing vector DB?
Yes. RAG-in-a-Box loads to Snowflake, Databricks, Pinecone, Weaviate, Vertex, pgvector, and supported on-prem options. The Kosmoy platform doesn't replace the vector DB; it ingests and queries it.
Can we use private embeddings?
Yes. Embeddings are provider-agnostic — public LLM embeddings, private fine-tuned embeddings, on-prem embeddings. Selected per use case.
How does it handle access control on retrieved chunks?
Source-document filtering applies the user's permissions at retrieval time. A document the user can't read is never returned, even if it matches the query.
What about hybrid search?
Out of the box. Lexical + semantic, configurable weights per use case, with re-ranking on top.
Ship a governed RAG system in days.
Walk through ingestion, vectorization, retrieval, and the governed answer path.