Blog
Thoughts on AI governance.
Perspectives from the team building the operating layer for responsible AI at enterprise scale.
The CAIO's First 100 Days: Building an Enterprise AI Operating Model
The Chief AI Officer role is the most consequential and least defined position in the C-suite. Here is a practical 100-day framework — Discover, Design, Deliver — for building the enterprise AI operating model that lets your entire organization use AI safely and effectively.
What Is AI Orchestration? A Complete Guide
June 16, 2026
12 min read
AI Agent Registry: The Foundation of Enterprise Agent Governance
May 26, 2026
3 min read
No-Code AI Agents: Democratizing GenAI Without Losing Control
May 23, 2026
7 min read
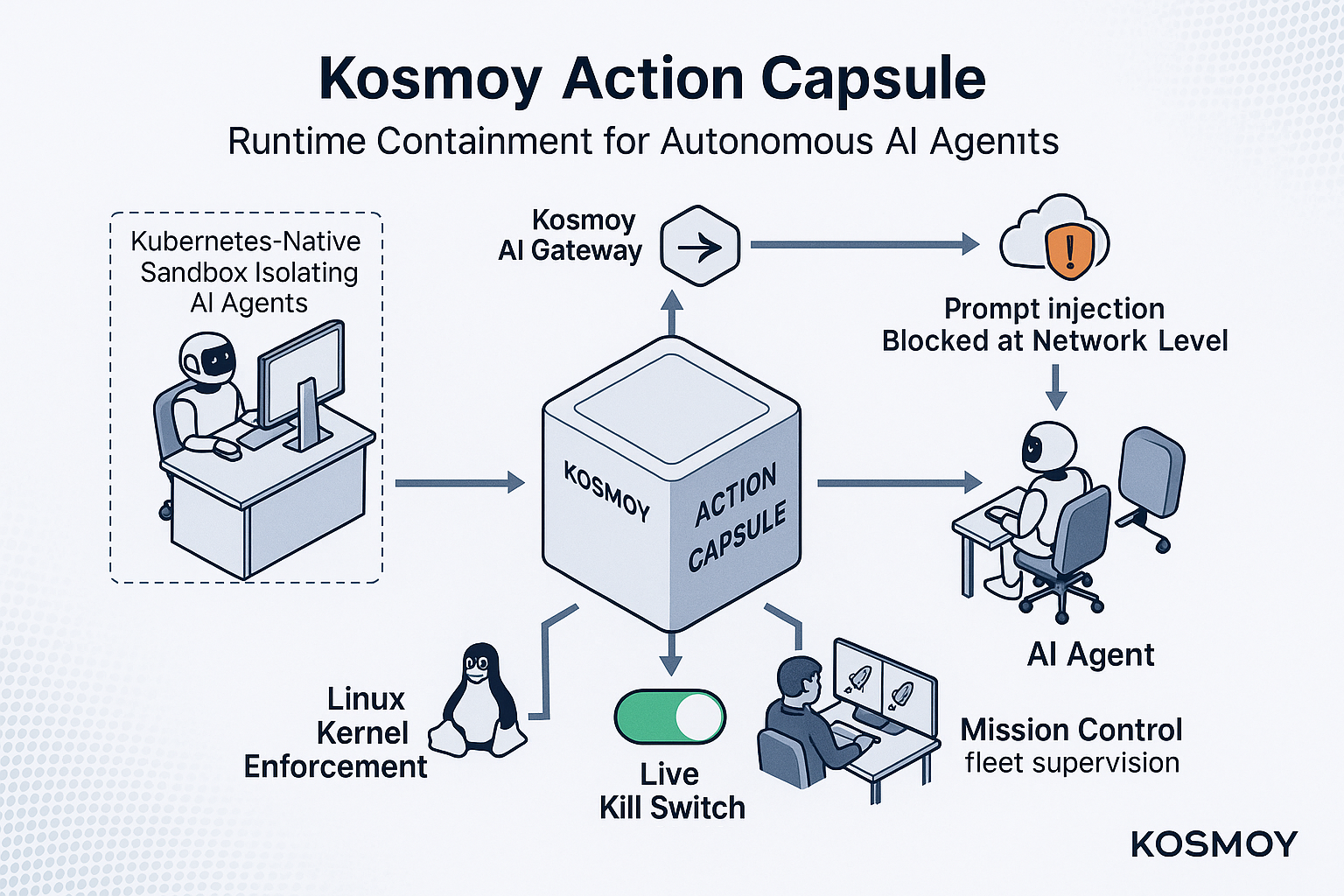
Kosmoy Action Capsule: Runtime Containment for Autonomous AI Agents
May 14, 2026
8 min read
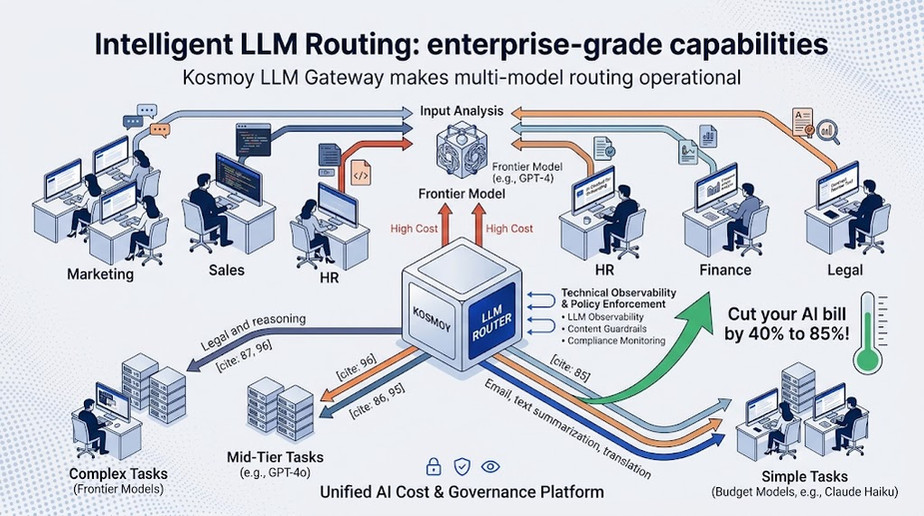
Smart LLM Routing: How to Cut Your AI Bill by 40%
May 4, 2026
5 min read

The EU AI Act Is Here: What CIOs Need to Do Now
April 20, 2026
6 min read
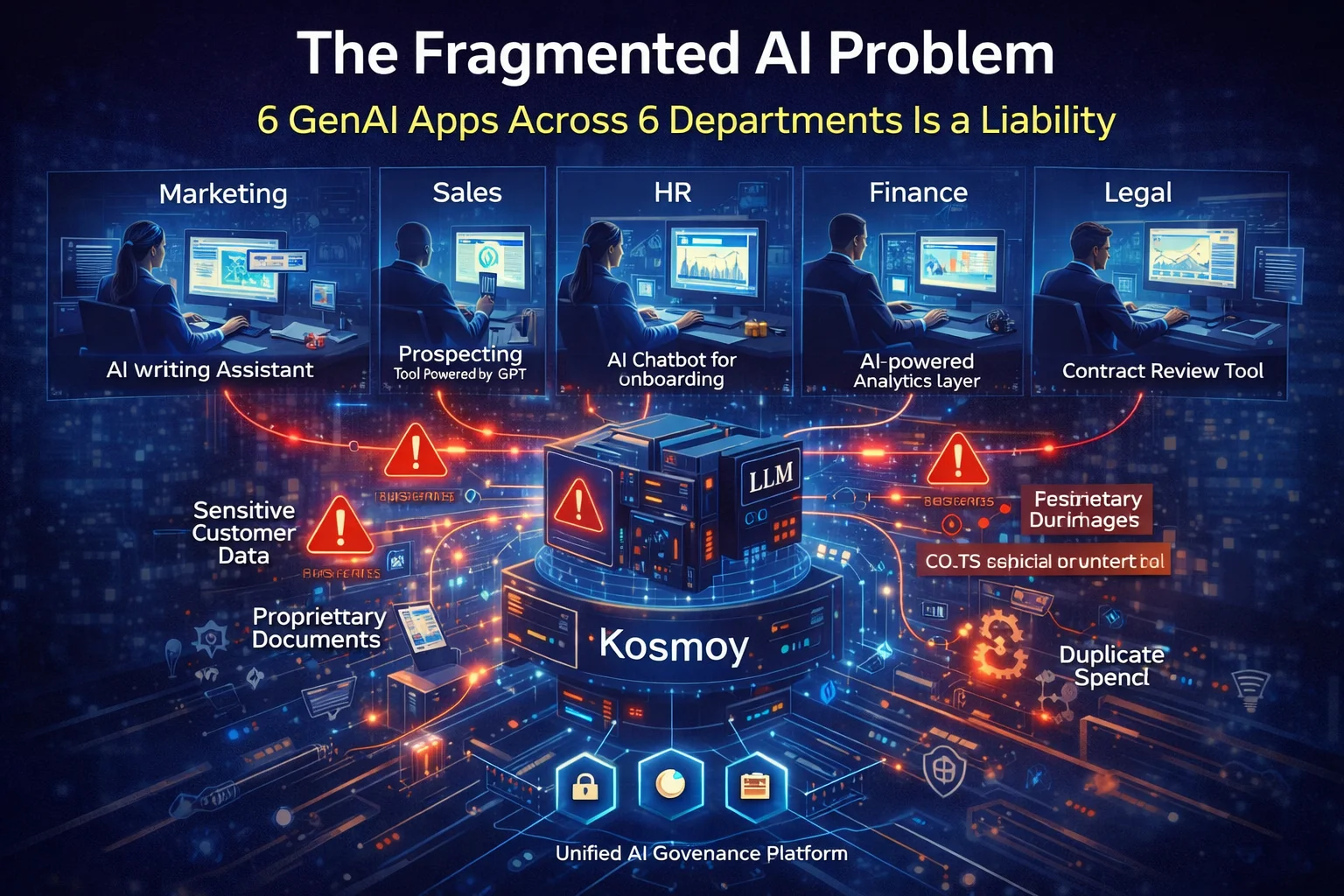
The Fragmented AI Problem: 6 GenAI Apps Across 6 Departments Is a Liability
March 31, 2026
5 min read

Shadow AI: Why Unmanaged Gen AI Is Becoming the Biggest Risk for Enterprises
March 25, 2026
5 min read

S&P Global Initiates Analyst Coverage on Kosmoy
March 1, 2026
3 min read
MCP Tracking: The Ultimate Guide to Model Context Protocol Tracking in 2026
February 15, 2026
9 min read

Why AI Needs a "Meter": Inside Kosmoy's Vision for Responsible Enterprise Adoption AI Systems
January 20, 2026
5 min read

6 AI Gateway Trends That Will Shape 2026
January 6, 2026
8 min read
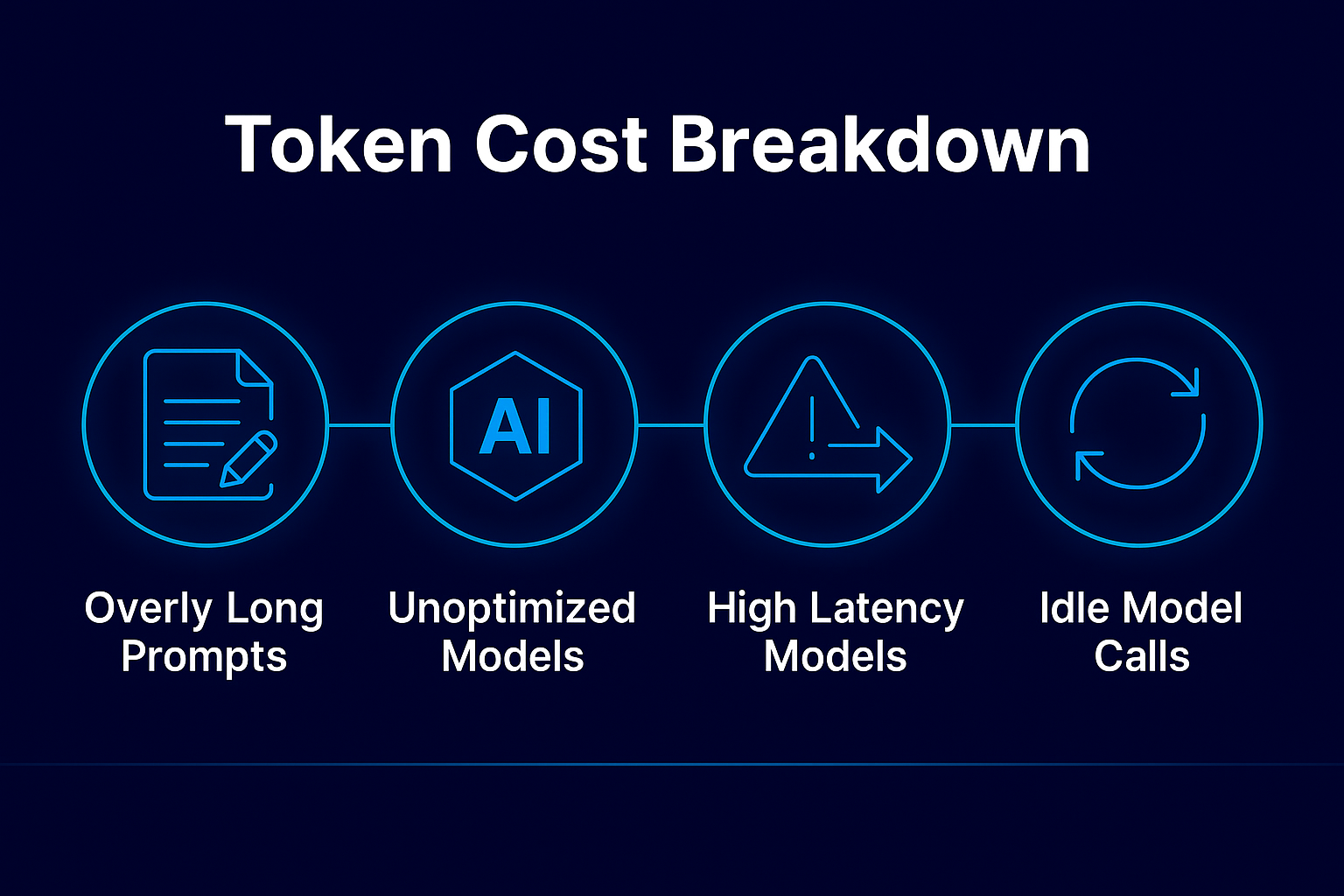
LLM Cost Optimization: Stop Token Spend Waste with Smart Routing
December 15, 2025
4 min read

Kosmoy Heads to Paris for Adopt AI – Grand Palais: CEO Umberto Malesci to Speak on AI & Data Sovereignty in Financial Services
November 19, 2025
3 min read

Simplifying ISO/IEC 42001 AI Governance with Kosmoy — from Policy on Paper to Controls at Runtime
September 24, 2025
5 min read

Deploying Generative AI Under DORA: Ensuring Compliance and Resilience with Kosmoy
September 22, 2025
8 min read

Kosmoy Sponsors the 7th Annual Artificial Intelligence in Financial Services Conference 2025
September 4, 2025
4 min read

LLM Gateway Compliance: Kosmoy's SLM Enforces the EU AI Act in Every Chat Turn
September 2, 2025
4 min read

Build vs Buy: Should You Code Your Own LLM Gateway?
August 13, 2025
4 min read

Top 5 Challenges AI Leaders Face in Adopting LLM Gateway and How to Overcome Them
July 10, 2025
4 min read

Mastering Generative AI Governance at Scale and LLM Gateway
July 3, 2025
5 min read

Kosmoy Sponsors AI for Financial Services Nordics 2025!
February 25, 2025
2 min read
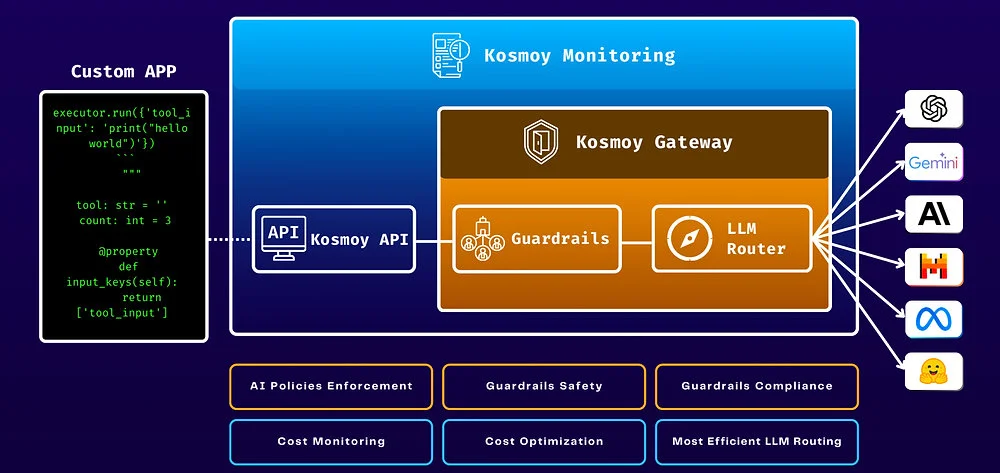
AI Gateway: Emerging Best Practice for AI Governance in the Enterprise
January 26, 2025
2 min read
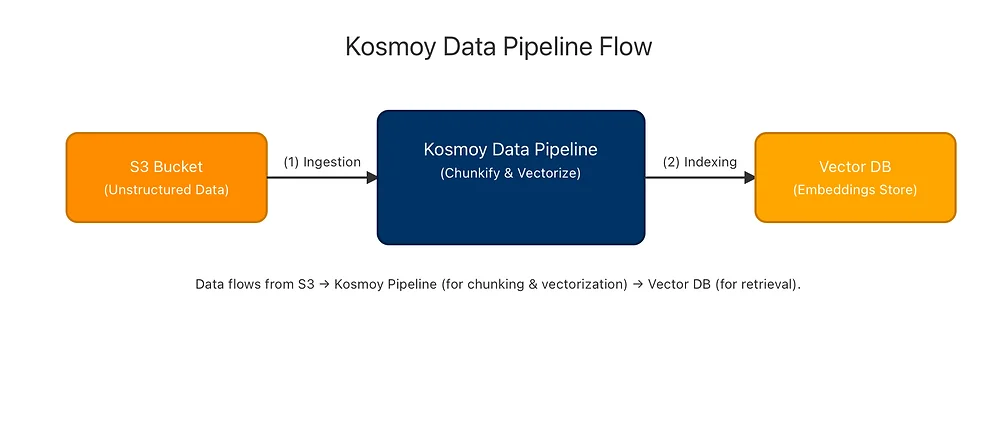
"RAG-in-a-Box" Solution
January 11, 2025
2 min read
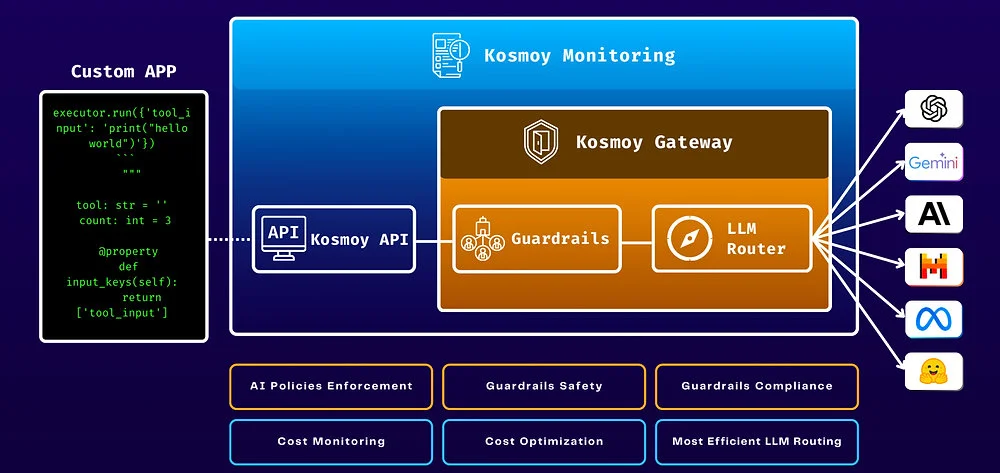
What is an LLM Router?
January 2, 2025
2 min read

What is GenAI Governance and Why Does It Matter?
October 30, 2024
2 min read
Ready to take control?
See how Kosmoy gives you visibility and governance over every AI interaction in your organization.
Or email sales@kosmoy.com.