Enterprise AI spending hit $8.4 billion in 2025 — more than double the year before. And for most organizations, a significant portion of that spend is going to waste. Not because AI isn't delivering value, but because every request, regardless of complexity, is being routed to the same expensive frontier model.
Asking GPT-4 or Claude Opus to summarize an internal FAQ is like hiring a neurosurgeon to take your blood pressure. The capability is there — but you're dramatically overpaying for what the task actually requires.
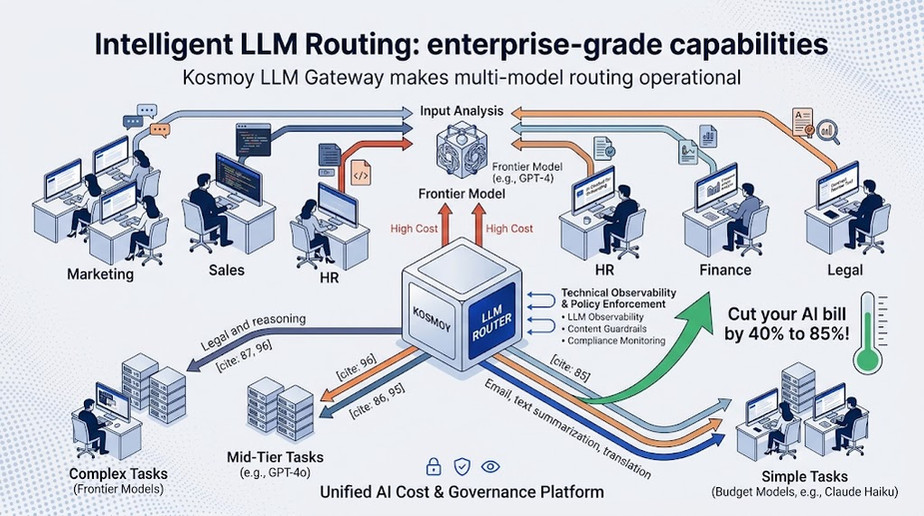
Smart LLM routing solves this. By dynamically directing each AI request to the most appropriate model based on complexity, cost, and performance requirements, enterprises are cutting their AI infrastructure bills by 40% to 85% — without meaningful degradation in output quality. Here's how it works, and how to implement it.
What Is LLM Routing?
LLM routing is the practice of intelligently directing AI queries to different language models based on the specific requirements of each request. Rather than treating every prompt the same way, a routing layer sits between the user and the models, evaluating each query in real time and sending it to the most cost-effective model capable of handling it well.
The logic is straightforward. Not all tasks require the same level of intelligence. A request to reformat a data table, generate a short email reply, or translate a sentence into another language can be handled perfectly well by a lightweight, low-cost model. A complex legal analysis, multi-step reasoning task, or nuanced customer-facing response may genuinely need a frontier model. LLM routing ensures each request gets exactly the model it needs — and no more.
In 2026, 37% of enterprises are running five or more models in production. The companies achieving the best cost efficiency are the ones treating AI model selection the way air traffic control treats aircraft routing: dynamically, intelligently, and based on real-time conditions.
The Cost Problem LLM Routing Solves
Nearly 40% of enterprises now spend over $250,000 annually on language models. At that scale, the price differential between model tiers becomes a major strategic lever. A frontier model like Claude Opus or GPT-4 can cost 20 to 50 times more per token than a lightweight model like Claude Haiku or GPT-4o Mini.
The typical enterprise query distribution tells the story clearly:
- ~70% of queries are simple enough to be handled by a budget model
- ~20% require a mid-tier model
- ~10% genuinely benefit from a premium frontier model
Yet without routing, all 100% are being billed at premium rates.
Implementing intelligent LLM routing across that distribution doesn't just reduce costs — it compounds. A 30% reduction on a $250,000 annual AI spend saves $75,000 per year. At $1 million in annual spend, a 40% reduction is $400,000 back into the business. These are not marginal optimizations. They are structural improvements to AI unit economics.
How Smart LLM Routing Works in Practice
Modern LLM routing operates on multiple signals simultaneously. A well-designed routing layer evaluates each incoming query across several dimensions before selecting a model:
Complexity classification — the router analyzes the prompt to assess whether the task requires multi-step reasoning, domain expertise, nuanced judgment, or simply pattern matching and generation.
Cost-performance thresholds — governance teams set rules defining which tasks are eligible for budget models, which require mid-tier, and which must escalate to frontier models.
Latency requirements — real-time customer-facing applications may route to faster models even if they cost slightly more; background processing tasks can route to slower, cheaper options.
Semantic caching — responses to semantically similar queries are cached and reused, eliminating model calls entirely. Production systems report cache hit rates of 20–40%, creating immediate cost savings with zero quality trade-off.
Fallback and failover logic — if a preferred model is unavailable or returns an error, the router automatically escalates or reroutes to the next best option, maintaining availability without manual intervention.
What Enterprises Get Wrong About LLM Cost Optimization
Most organizations approach AI cost reduction by negotiating better pricing with a single vendor, or by setting blanket limits on token usage. These approaches miss the point. Token caps reduce AI usage. Smart LLM routing reduces AI cost — while preserving or improving the experience for end users.
The other common mistake is treating LLM routing as a developer problem to be solved at the application level. When individual teams implement their own model-selection logic, you end up with inconsistent routing policies, no centralized visibility into cost or quality, and no way to enforce governance rules across the organization.
Effective LLM routing needs to be implemented at the infrastructure level — not application by application, but across the entire enterprise AI stack. That means a centralized gateway that intercepts all LLM traffic, applies routing logic consistently, and provides unified visibility into cost, performance, and quality across every model and every department.
How Kosmoy Makes Enterprise LLM Routing Operational
The Kosmoy LLM Gateway is built specifically to make intelligent LLM routing an enterprise-grade capability, not a custom engineering project. By centralizing all LLM traffic through a single gateway, Kosmoy gives AI governance teams the ability to define and enforce routing policies across every application, department, and model in the organization's AI stack.
Routing rules in Kosmoy are configurable without code. Governance teams can define which use cases route to which model tiers, set cost ceilings by department or application, and monitor real-time spend against budget thresholds — all from a unified dashboard. When a routing rule is updated, it applies instantly across every application touching the gateway, eliminating the coordination overhead of application-level changes.
Kosmoy also combines routing with governance. Every routed request is simultaneously screened for PII leakage, EU AI Act compliance violations, and content policy breaches — meaning cost optimization and compliance enforcement happen in the same infrastructure layer, with no performance trade-off.
The result: enterprises using Kosmoy get the cost benefits of intelligent LLM routing without the engineering overhead of building and maintaining custom routing logic — and without sacrificing the governance controls the business requires.
The Bottom Line
LLM routing is no longer an advanced optimization for AI-native companies. It is a baseline practice for any enterprise serious about deploying GenAI at scale. As model portfolios expand and AI usage grows, the cost of not routing intelligently compounds every month.
The organizations that will lead on enterprise AI in the next two years are not necessarily those with access to the best models. They are those with the infrastructure to use the right model, for the right task, at the right cost — every single time.
Want to see how Kosmoy's LLM Gateway handles intelligent routing at enterprise scale? Learn more at kosmoy.com