PIPELINES
From documents
to AI-ready data
Document ingestion engine for RAG workflows. Parse, chunk, and embed documents into vector databases with configurable processing stages and full run tracking.
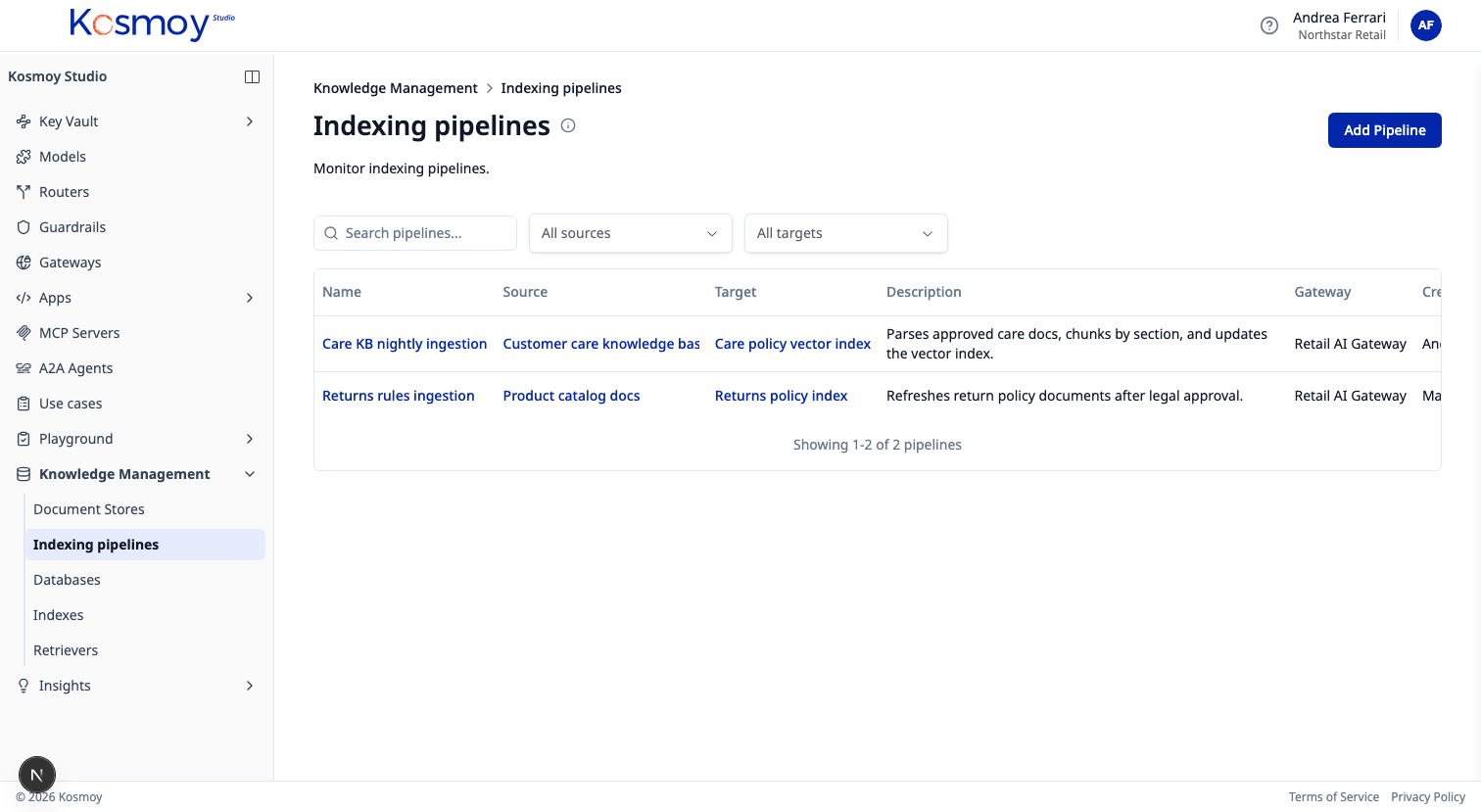
Building production RAG starts with clean data pipelines. Kosmoy Pipelines handle the entire document lifecycle: parsing PDFs, Word, HTML, and 50+ formats; intelligent chunking with configurable strategies; embedding into vector databases like Snowflake, Databricks, and Weaviate. Every pipeline run is tracked with detailed logs, status monitoring, and automatic retry on failure.
Parsing Strategies
Extract content from PDFs, DOCX, HTML, Markdown, and more. Configure parsing rules per data source type for optimal content extraction.
Chunking Strategies
Split documents with max-size, hierarchical, or hybrid chunking. Configure overlap, chunk size, and boundaries for optimal retrieval.
Embedding & Vector Storage
Embed chunks into vector databases — Snowflake, Databricks, Weaviate, and others. Automatic embedding model selection and batch processing.
Pipeline Runs
Track every pipeline execution with status monitoring (Running, Completed, Failed, Stopped), detailed logs, and paginated run history.
Deletion Strategies
Manage document lifecycle with configurable deletion strategies. Clean up outdated embeddings and maintain vector store hygiene.
Build production RAG pipelines
See how Kosmoy Pipelines turn your documents into searchable, AI-ready knowledge.
Or email sales@kosmoy.com.